Microcontroller’s Port Impedance and Emissions Dependence on Instruction Set
Black Box Model
Introduction:
The overarching goal of this project is to develop a black box behavioral model for electronic effects due to EM interference. A fully developed behavior based model can aid in the development of a predictive capability of the effects of side channel attacks on electronic circuits. The theoretical underpinnings of this predictive behavior are based on the random coupling theory.
Instruction Dependent Port Impedance
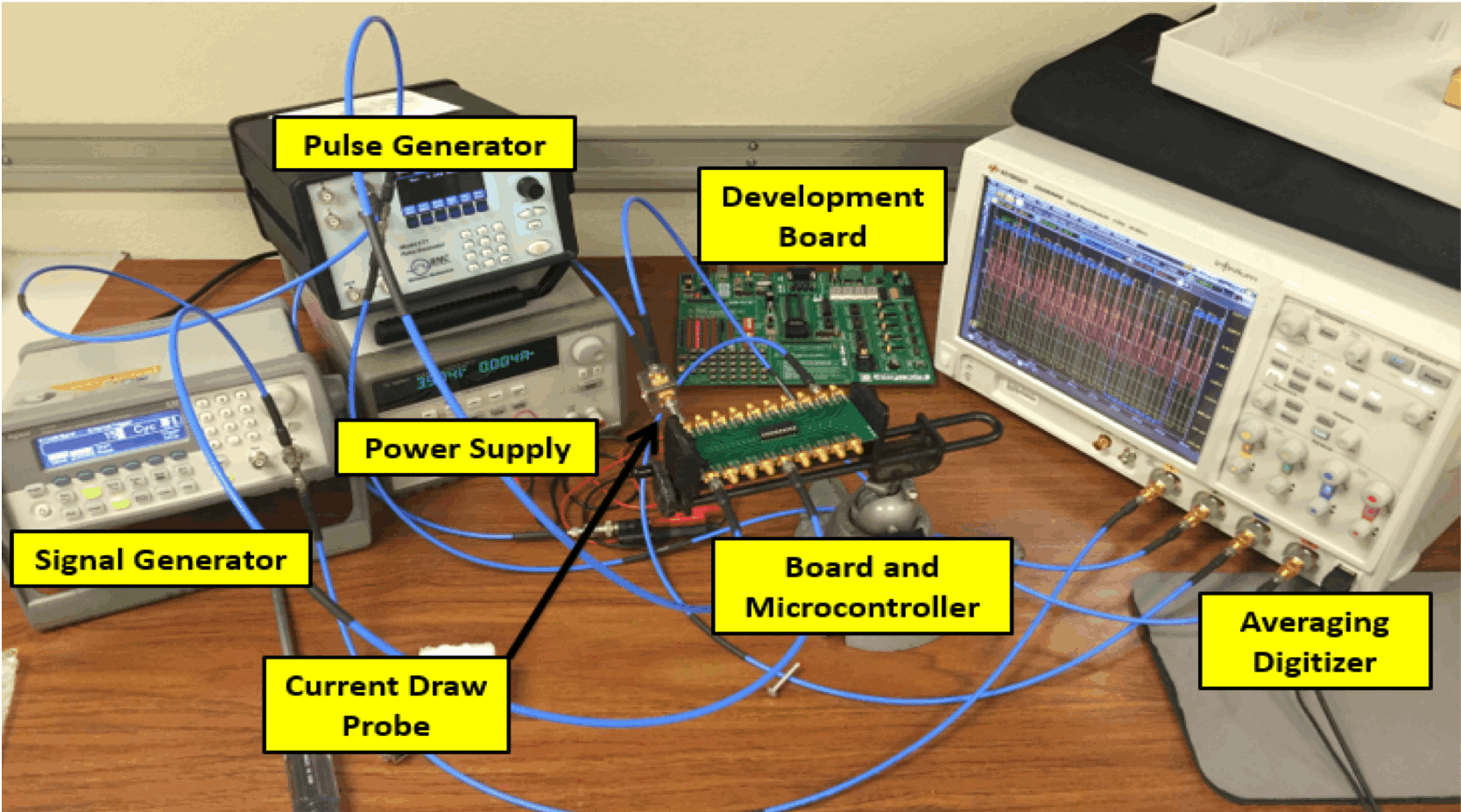
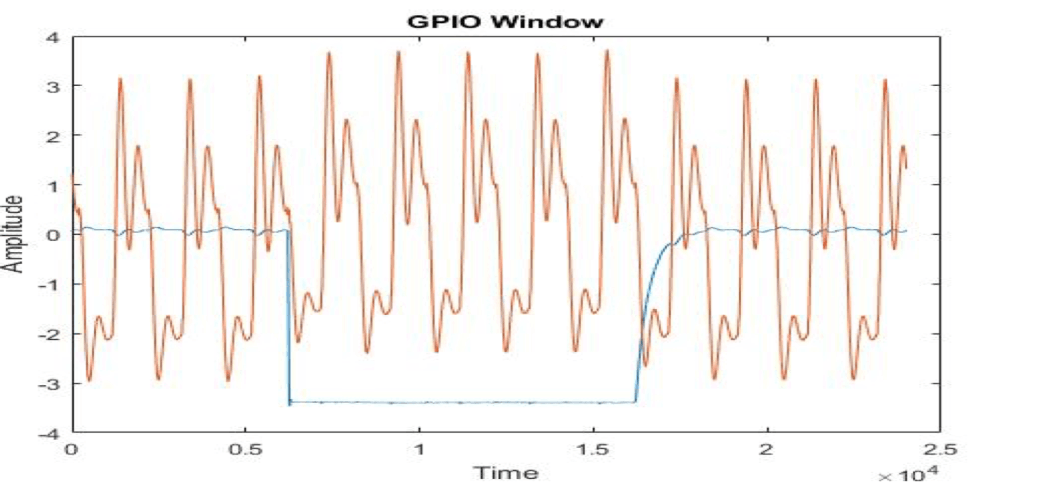
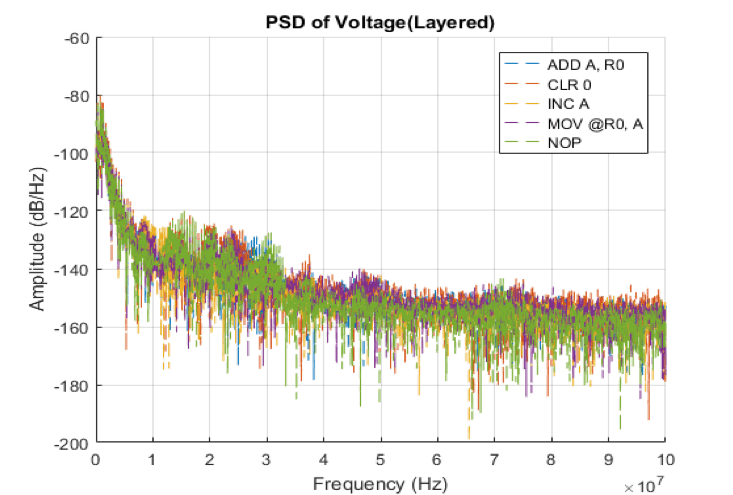
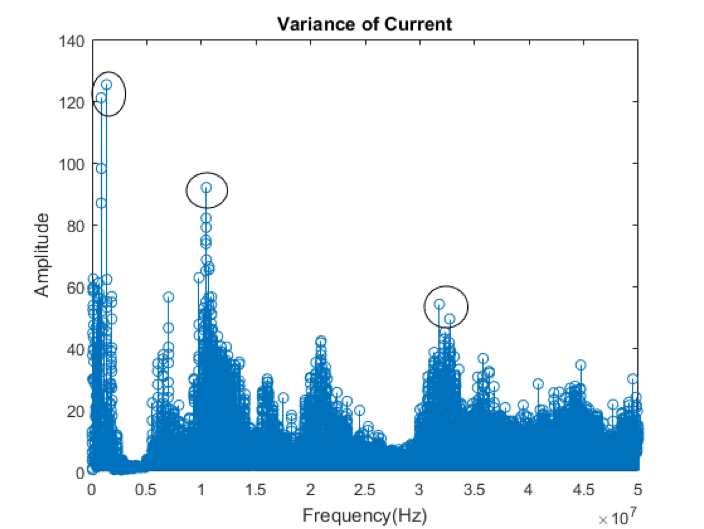
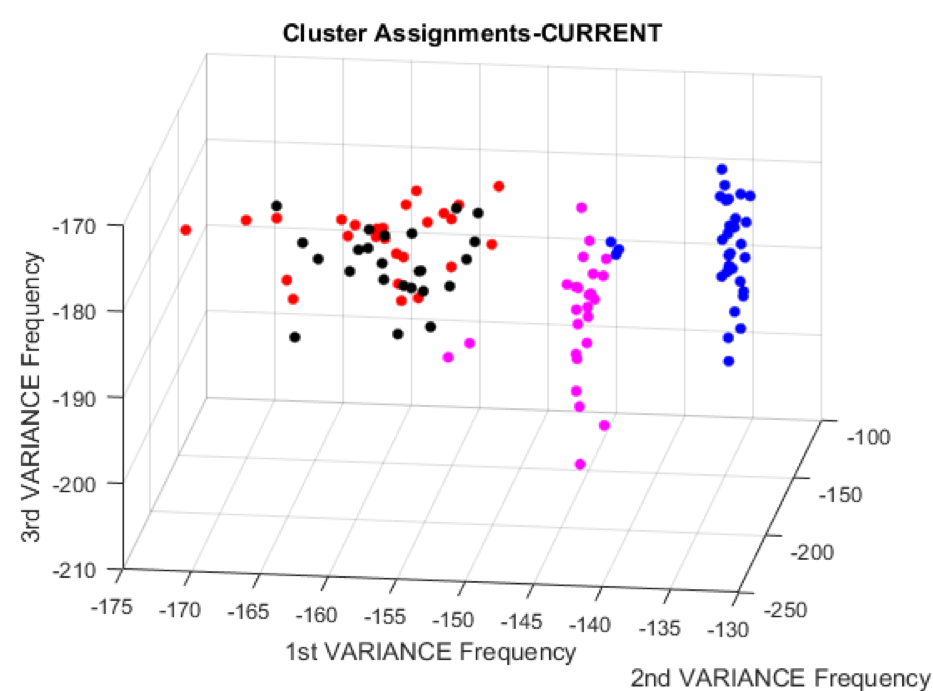
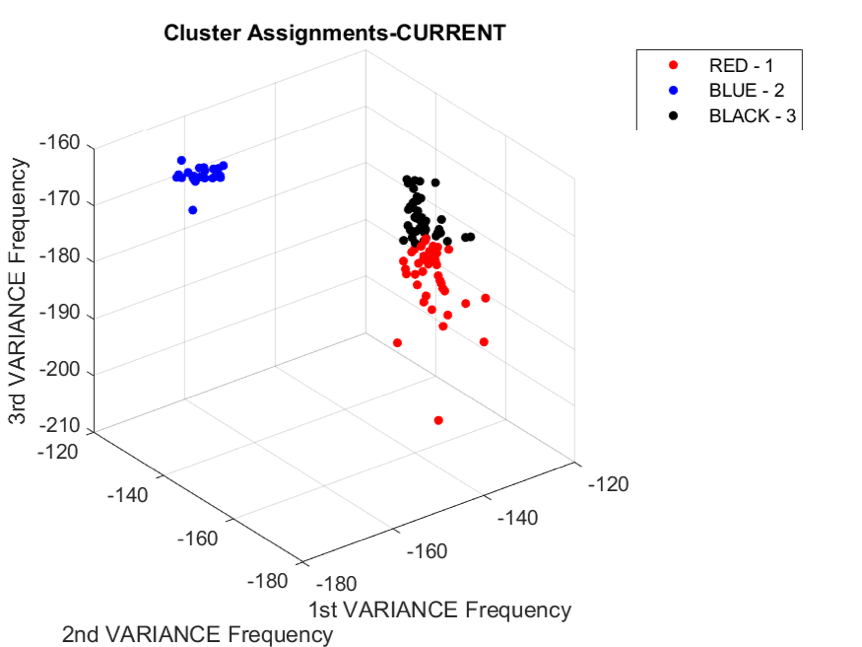
As part of this project our goal is to measure and classify voltage, current, and EM emissions of an 8 bit microcontroller operating under different instructions. Fluctuations which are dependent on instruction will be measured which will reveal distinct patterns in microcontroller behavior.